Tag: statistical-power
-

Estimating long-term detection, win, and error rates in A/B testing
How to estimate the probability of detecting (a positive) treatment over a series of experiments? I use an (admittedly weird) fusion of frequentist concepts and Bayesian tooling to get to an answer.
-

Getting faster to decisions in A/B tests – part 2: misinterpretations and practical challenges of classical hypothesis testing
Null hypothesis test of means is the most basic statistical procedure used in A/B testing. But the concepts built into it are not exactly intuitive. I go through 5 practical issues that anyone working with experimentation in business should be aware of.
-
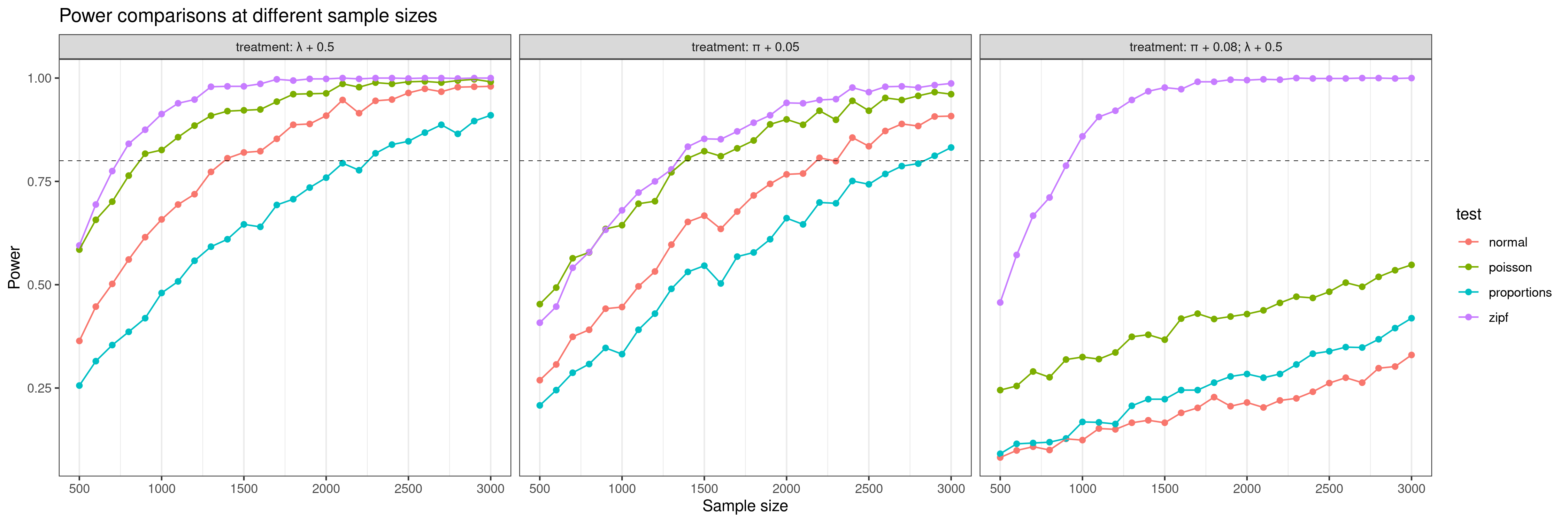
A/B testing, zero-inflated (truncated) distributions and power
Naive A/B testing just uses t-tests or proportion tests, with the assumption that at large sample sizes, the right statistical test does not matter that much. I explore the case of a zero-inflated upper-bounded Poisson distribution and find that using the wrong test can require 3x the sample size to achieve the same statistical power,…