
(see also: part 2)
My current job involves supporting product managers in setting up and running experiments (a.k.a. A/B tests). One of the key questions in running such experiments comes down to time: how long an experiment needs to run? When will we have the results? Can we look at interim results and make a decision based on them? Everybody wants to learn from A/B tests as quickly as possible.
In my experience, two main factors influence the time it takes to run the experiment: the statistical and the business ones. Often, the business factors are much more important – especially if you have a large user base that makes it easy to achieve the required sample sizes.
These business factors come down to choosing the metric on which the decisions will be based. For example, it’s easy if you’re trying to improve the purchase funnel on the website, and the metric of interest, conversion rate, is available instantly. But other times, you may need to wait a while before the metric is available. For example, if you are testing whether a feature increases the ‘stickiness’ of the app, an appropriate metric that measures it may not be available up to 4-5 weeks after the experiment starts. Another important consideration is novelty effects. Facebook’s experimentation team recently wrote about an experiment where they tracked the long-term effects of a change.. for two years! Importantly, they learned that the long-term impact was opposite from the short-term. Novelty effects, more broadly, are one of the more interesting challenges in A/B testing.
I believe the choice of the metrics is much more important than one of the statistical procedures. However, once the metrics have been decided, the inevitable dance of “what do statistics tell us about required sample sizes” begins. The basic tool for assessing experiments is null hypothesis testing (NHT). In it, the sample size (and, thus, the experiment runtime) is a key component that you trade off for sensitivity (ability to detect an effect if one is present, a.k.a. power) and specificity (ability to avoid false positives; closely related to statistical significance) of the test.
However, NHT has limitations. It does not allow peeking at results early. I also argue that it is unintuitive, and it’s questionable whether the concepts NHT operates with (a “binary” yes/no answer, concepts of statistical significance and power) are the most useful in a business setting.
Here’s a small example. Imagine you are discussing an experiment with a product manager, and the question of power level (rate of detecting an effect when such an effect is true; a.k.a. true positive rate, a.k.a. sensitivity) comes up. She asks: “soo.. we always use a power level of 80%, and we ran these past five experiments with ~10,000 users each, and that implied a minimum detectable effect of 1.5% on our key metric.. but we detected an effect of 0.8% on two of them. How come? I thought the point of minimum detectable effect was that it’s a minimum change we can detect, but we seem to be able to detect lower changes, too?” There is a statistical answer to this question, of course. But it is bloody confusing.
I set out on an exploration to understand how the industry tackles these issues. A lot of funky problems come up in A/B testing that wasn’t my focus this time: non-stationarity, SUTVA violations that are incredibly important in marketplaces & social networks (here’s LinkedIn’s ego-clustering approach to mitigating this issue), mitigation of winner’s curse, a need to re-weight results towards your ‘target customer’ population, or situations where you cannot run A/B tests at all, and need to rely on causal inference techniques instead (StichFix has a some [1, 2] of great posts about different problems they address with causal inference approaches; Netflix has a post with a survey of methods they use). Not to mention the general caveats and limitations of A/B testing or broader culture and data infrastructure considerations.
Instead, I wanted to focus on understanding what teams do to 1) get to decisions faster and 2) alternatives used that may be more intuitive than NHT. This blog post is a summary of what I found so far. In future posts, I will dive into the most interesting methods to fully understand what they promise and what they deliver.
Approaches for solving the ‘peeking problem’
To begin with, there is a family of procedures that address one of the best-known limitations of NHT – the inability to interpret interim results without inflating false positive rates (a.k.a. the peeking problem).
- Sequential hypothesis tests. These procedures allow analyzing the results a predetermined number of times without inflating error rates. The pharma industry has been using them for a long time to determine if clinical trials need to be stopped early. Daniël Lakens’ online book Improving Your Statistical Inferences has an excellent overview. Etsy team wrote about an implementation inspired by these approaches, and Netflix also discusses using such designs.
- “Always valid p-values” / confidence sequences. They ensure your false positive rates are not inflated no matter how many times you peek. One approach to calculating them, mSPRT, is used in Optimizely, one of the largest A/B testing vendors, and has nice, closed-form solutions to Gaussian/Bernoulli distributed random variables (R package also exists). Another approach is implemented in
confseqR/Python libraries; it relies on a different kind of maths to guarantee non-inflated error rates. I also found a few papers that lay out other procedures to achieve the same goal: Confidence sequences for sampling without replacement; and Empirical Bayes Multistage Testing for Large-Scale Experiments.
My current intuition about these approaches is that “there’s no free lunch”, and you need to sacrifice a bit of sensitivity to limit false positive rates. I found a few nods in that direction, including a blog post from Wish that discusses mSPRT and notes that it yields lower power. They call it “satisfactory”, but based on the chart in the blog post, it seems it yields ~40% power for an effect size that a simple t-test would produce 80% power. I am not sure if that is satisfactory. The Empirical Bayes Multistage Testing paper mentioned above also discusses how their approach is superior to mSPRT, particularly from a power perspective.
Does high sensitivity/power matter, and should we be willing to sacrifice some of it in favor of specificity? I think it’s a question of business context and experimentation maturity.
If you are at a maturity stage where A/B testing is about tiny incremental changes, where you run 100s of experiments simultaneously in a self-service manner, then avoiding false positives may matter more than missing out on one of those changes that mattered, but you did not detect.
But I think many businesses are not there (yet), or their product needs experimentation with larger changes than color or font size to make a difference. At WW, where I work, we tend to experiment with changes that require larger engineering and design lift, such as a different search algorithm, a redesign of how user points’ budgets are presented, a new recipe experience. These are not trivial changes, and we are unlikely to have 100s of experiments running daily. The metrics we want to move are not instant, either. It may make more sense to care about false negatives in this business context. It’s just a different setting than testing whether font sizes increase conversion.
I am also conscious that power is a less understood concept, unlike its well-known sibling, the statistical significance, that is featured in all statistics 101 classes. Part of me worries that so much focus is on avoiding inflated false positive rates because of this imbalance. How many businesses use the default values of 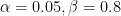
From that perspective, I look forward to taking sequential testing approaches for a spin and understanding sensitivity implications.
Bayesian methods
It is not hard to find articles convincing to switch over to Bayesian methods for A/B testing. They can promise wonders – here’s an example from one of them.

Of course, Bayesian statistics is no magic, and I would argue that at least 3 of the above statements are wrong. (for the record – I love Bayesian statistics! I overuse it in my day-to-day work). Yes, Bayesian methods provide tools that may be more intuitive to interpret than NHT and p-values, but from what I have gathered, the main reason why one should consider these methods is that they change the way one quantifies the outcome, not because they are immune to peeking (they are not!) or because sample size does not matter (how could it not?).
In the simplest setup (posterior of outcome differences), they switch the conversation from “is variant B better” to “how much do we think variant B is better”. But even more interesting are two other methods of quantifying outcomes – ROPE (region of practical equivalence, where outcomes are deemed “the same” if they only differ by amounts that “no one cares about”) and expected loss (which aims to minimize the loss from making the wrong decisions).
Some of the best readings I found about Bayesian A/B testing & technical resources (Bayesian stats can get computationally complex!) include:
- An overview of Bayesian A/B testing methods by Claudio Bellei
- Formulas for Bayesian A/B testing by Evan Miller
- The Bayesian New Statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective, a paper from J. Kruschke and T. Liddell that covers the ROPE procedure & estimating power in Bayesian methods.
- The Power of Bayesian A/B Testing by Michael Frasco, then at Convoy, covers the procedure that uses expected loss as a metric and is accompanied by an R package.
- Is Bayesian A/B Testing Immune to Peeking? Not Exactly, a post from David Robinson that explores what exactly Bayesian A/B testing promises and what it does not.
- Solomon Kurz has written a series of blog posts about Bayesian power analysis (I suppose that’s proof that sample size matters). There’s also something called pre-posterior analysis that can be seen as equivalent to power analysis in a Bayesian setting. I found one paper (Pre-posterior analysis as a tool for data evaluation: Application to aquifer contamination) that seems promising.
- Continuous Monitoring of A/B Tests without Pain: Optional Stopping in Bayesian Testing, a paper by A.Deng, J.Lu, and S.Chen (I haven’t read it yet, but the abstract sounds promising!)
- Inferences on the Difference of Two Proportions: A Bayesian Approach, a paper by Thu Pham-Gia, Nguyen Van Thin, and Phan Phuc Doan contains some helpful content when considering the calculations behind Bayesian A/B testing.
- Bayes AB package in R for “fast Bayesian A/B testing”.
- Bayesian inference at scale: Running A/B tests with millions of observations and Bayes is slow? Speeding up HelloFresh’s Bayesian AB tests by 60x from pymc labs that discuss tricks to making Bayesian inference faster (hint: for basic tests, you won’t need it, conjugate distributions will be your friend instead).
That’s quite a lot to go through. The most exciting part of the upcoming adventure 🤩.
Other ways to get to ‘yes’ (or ‘no’) faster
Something I did not know before starting the research is the category of techniques focused on variance reduction. To quote Davis Treybig:
The sample size you need to collect in an experiment is ultimately a function of two things: the effect size of your treatment, and the variance of the metric you are measuring. A number of techniques can be used to dramatically reduce the effective variance of the metric you are measuring, allowing for a substantial increase in your experimental throughput.
The Experimentation Gap
(Davis’ post The Experimentation Gap is a great read to understand what experimentation infrastructure & culture look like at the companies at the frontiers of using A/B testing).
On a high level, these procedures include:
- Stratification. Suppose you believe that subgroups of users in test & control groups may have either lower variance of the metric you are interested in or may react differently to the treatment (a.k.a. heterogenous treatment effects). In that case, you may get higher statistical efficiency by stratifying the results by subgroups and performing analysis on that level.
- Covariate adjustments; often referred to as “CUPED”. The general idea is that you work not with raw metrics data but instead adjust it based on other data you may have on the users. In the most basic version, you may work with residuals produced by a linear regression where your metric is the outcome variable.
Davis has a list of blog posts covering these techniques in his Experimentation resources collection that I am keen to get through; a couple of other good resources in this space I found include:
- Anytime-Valid F-Tests for Faster Sequential Experimentation
- Through Covariate Adjustment, a paper by Lindon et al. seems to combine always valid p-value & covariate adjustment techniques
- Improving the Sensitivity of Online Controlled Experiments is a paper from Nexflix that discusses post-stratification and CUPED.
- Statistical Challenges in Online Controlled Experiments: A Review of A/B Testing Methodology, a paper by Larsen et al., discusses a bunch of statistical challenges and solutions in A/B testing, including variance reduction techniques.
As I was finishing this blog post, I came across a similar, on a first impression, but after a deeper look, I realized – a fundamentally opposite – approach recently discussed by Dropbox. Instead of using covariates to reduce unexplained variance and test the impact of treatment on residuals, they go the other way around. They build an ML model to predict an outcome based on many covariates and then estimate if the treatment influenced the predictions. While Dropbox’s use case is a bit different, I think it’s helpful to put this approach under the same category – it is, too, about increasing the speed of getting results. And while I see the value of “being able to estimate expected revenue just after a few days” (magic, isn’t it?), that approach bakes in some hidden assumptions that, in my view, may be very damaging if not guarded against.
What’s next
That’s it for part 1!
Next, I plan to write up what is wrong with NHT. While it has been covered a lot of times, there are a few underappreciated aspects that I would like to dig into. I will also use it to set a comparable basis for assessing all the techniques. And then onto sequential testing, Bayesian methods, and variance reduction techniques. It may take a while, but I hope I’ll get there!
Already written:
1. Common misconceptions & challenges with NHT